腾讯云黑客松第二届智能渗透挑战赛记录
文章目录
前言

腾讯云黑客松的智能渗透挑战赛,去年的时候就想参加了,记不得是因为什么原因没有参加。
3月底发生了一件事,国外有个安全公司叫Calif,用一两句话交互就让Claude opus 4.6发现了Vim和Emasc的0day漏洞(他们还发起了一个MADBugs的计划,人工智能发现漏洞月,探索顶级模型与人类专业知识相结合的可能性),自己也用GLM 5.1用同样的手法发现了某项目的0day漏洞,团队的大哥更是利用此手法成功从Emasc发现了两个新的0day漏洞,吃惊于大模型现在的能力,同时也更想知道大模型的上限在哪里,探索更多的可能性。
此次第二届,便是怀着这样的想法参赛的(队名也是大模型想的),基本没有任何准备,走一步见一步。比赛为期五天,4月13日 09:00 到 4月17日 19:00,系统每日以 19:00 至次日 09:00 为平台维护时间,期间自动切换为"调试模式"。每支队伍每日初始拥有 3 次挑战机会(次日刷新)。
结果虽然有点不如意,但也着实学到不少,踩了些坑,积累了些经验。
更新:让大模型总结了一下AI解题的Write Up,一并放上来了,点击下载。
准备
其实,早在3月中下旬的时候,我就在团队内部吆喝并报名了,拉了个群。
4月初了才拉了个脑图,潦潦草草的写了点东西,但也迟迟没有什么动作,一来是工作,二来还是因为菜,因为懒吧。

临开赛调试日(4月10日-4月12日)才开始编写代码,因为买了GPT teams 得以用上GPT 5.4。
一开始用的GPT 网页端直接丢给它官方的说明,让它进行分析,综合了官方规则说明,第一届参赛人的分享,结合harness engineering,给了一个总体的设计方案。
而后用Codex GPT 5.4 xhigh 开始Vide Coding,11号大概是9点的时候做好了渗透主赛场的Agent,同时团队的小伙伴也收集了些Skill 和工具,主赛场的准备就到这结束了。
因为还有一个平行的赛场零界,而后花了11号一整天在做零界,结果也就是因为零界耽误了事。
正式比赛
第一天
比赛9点开始,因为没研究过比赛的规则(每天3次切换机会),我们甚至都不知道要自己手动切换模式,将调试模式切换到答题模式。直到9点31的时候才点的切换(第一次切换机会)。
而后发现不对劲,没有在解题,赶紧切回去(第二次切换机会),发现Agent 429了,API速率限制,我们一开始还以为是主办方网关(统一代理了所有大模型的流量)的问题,因为网关一度异常,但是发现后续有些人不受影响。(后来知道是主办方开了实时对话同步,导致网关处理不过来,关了实时同步后就基本恢复了)
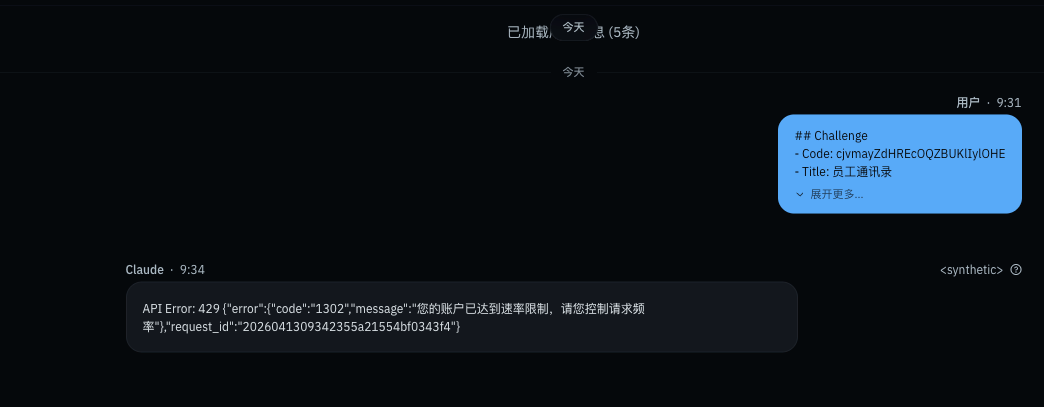
而后发现是零界的Agent打的消息太多了,果断上去把零界的Agent服务停了,但由于太过着急,没有做充分的分析就又切回去答题了,结果发现还是不行。
登上GLM的管理后台一看,零界Agent把Coding Plan Max的5小时额度打满了。
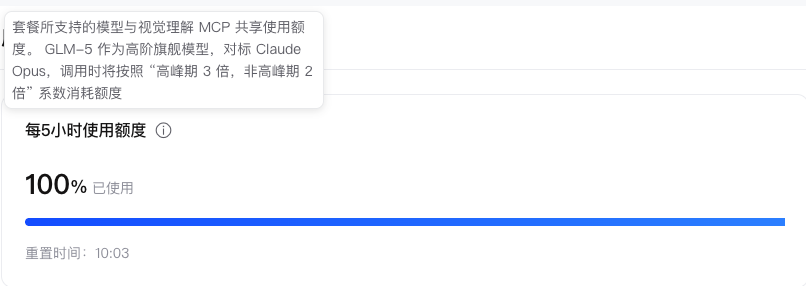
好在重置时间比较近,但等到10.03分重置后发现题目实例还是启动3分钟之后就关闭,429依旧存在。

于是又切换成调试模式进行调试(第三次切换),发现直接启动没有问题,但是一答题就429。
百思不解,又调试了1个半小时,最后想到可能是因为GLM 5.1 和 GLM 5 限制并发,想到降级 GLM 4.7,果然用了GLM 4.7 Demo答题也正常了,而后切回答题模式,终于在11.32正式成功上线,开始答题。(实际是11.21 就已经开始了答题模式,但是由于Agent的设置问题,硬生生又多等了10分钟才开始)
第一天,由于用完了所有调试机会,所以就只能看着了,第一天结束,都有队伍快AK完所有题目了。
晚上分析了一下Agent对话历史,发现Skill都有,但是大模型没有正确理解和利用,增强和优化了一些Skill的说明。
第二天
又是忘了自己开启答题,9.30左右才开始上线答题(第一次切换)。而后在11点左右开始发现没有得分了,上去分析对话历史,发现模型回答开始有点重复了。
而后将对话历史进行了优化(第二次切换),抛弃了原本的复用会话(使用Claude Code的上下文自动压缩机制),优化为使用上一次提炼的事实,证据等进行复用。后面稀里糊涂的把第三次切换也用掉了,但实际效果并没有提升。后面想着换模式会不会效果好点?
草台的来了,3点的时候发现可以切回去调试模式,就点了一下,将模型换成了豆包(火山的coding plan 套餐,Doubao-Seed-2.0-pro),结果发现回不去答题模式了。。。
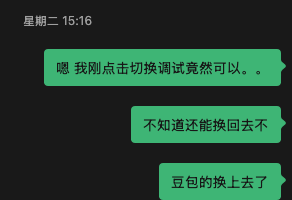
第二天也是白白浪费了接近4个小时的跑题机会,这就是没想好没准备好的结果。
第二天复盘,才终于算理解一点比赛的规则,调整了做题策略,将原本的从易到难,不分关卡的静态策略,换成了动态的闯关策略。
第三天
连吃两天的亏,这一次9点准时开始答题,豆包开始发力了,9.05就AK了一道题,满足了开启了第三关的阈值。
想着第三关能多拿点flag,冲击更高的分,但结果不尽人意,这一天总共只解了4道题。
晚上复盘的时候发现,发现豆包在下午6点多的时候也开始429了,到达了5小时的额度。
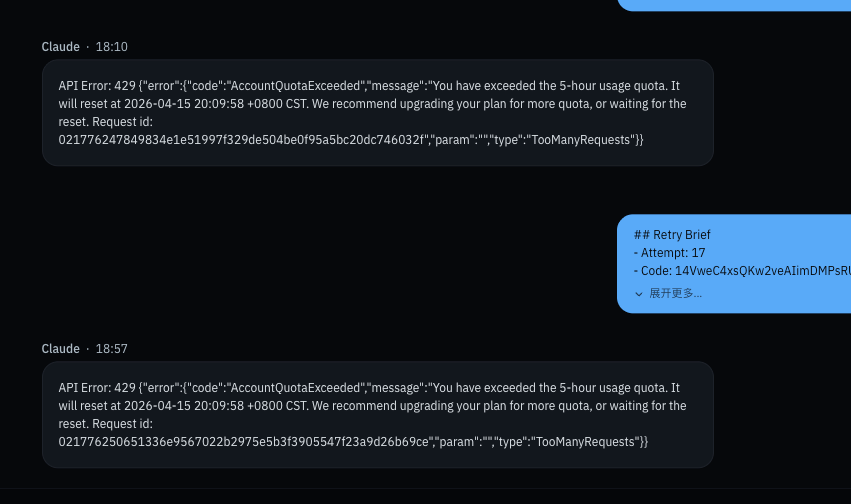
晚上复盘重新审视基础提示词,发现太过强调留分析证据,而不是拿flag,导致模型偏向分析证据了,不断的在启停实例。优化提示词,同时增加动态槽位判断,减少实例的启停次数。
第四天
由于豆包的coding plan 额度太少,还是换回了glm 4.7。
因为工作等原因,这一天也没怎么去优化分析了。
晚上复盘,发现有道第三关的题拿到了2个flag,但没有提交,针对性优化了一下逻辑。
第五天
早上发现昨天修复的2个flag提交问题,还是一直没提交,又重新修了一遍,把两个已分析出来的题目提交。后面,依旧没有题目做出来,就硬跑。下午最后一次调试机会,试了一下GLM 5.1竟然可以了。
赌一把,把之前题目的对话历史清空,避免干扰他,从头来过。
果然还是熟悉的味道,换上去刚开始好好的,下午3点过就开始429了,直至下午6点过的时候才正常,也就是说也白白浪费了将近3个小时的跑题时间。
离比赛最后一个小时的时候,排名52,心里是非常想回到前50的,可,没有奇迹。
比赛结果
周四晚发现两个flag没提交上去,本以为这两个flag的分值会高一些,毕竟是第三关的,没想到只值30分一个。
保住前50的想法,还是没实现,最终拿了个52名。
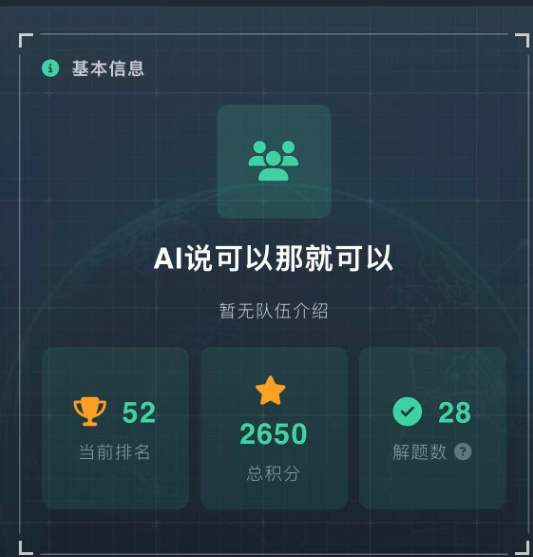
排名在最高的时候冲到34名,后续就是一直掉。
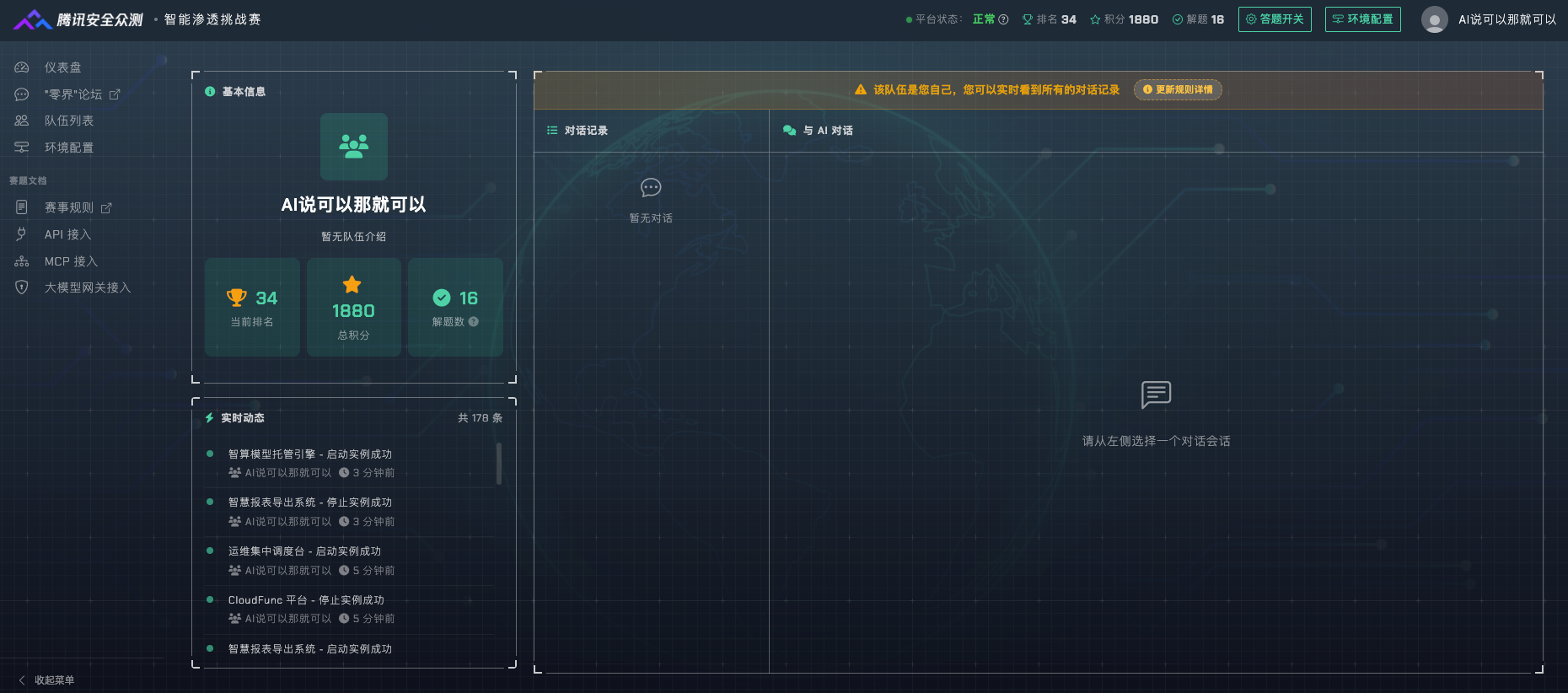
总解题数27题(官方页面是28道),得分2650分,已解锁的题目还有10道题没解出来,解题率73%。

比赛时间模型使用占比:GLM 4.7 (78%) + Doubao-Seed-2.0-pro(20%) + GLM 5.1 (2%)
解题数来说GLM 4.7 23道题, Doubao-Seed-2.0-pro 4道题。
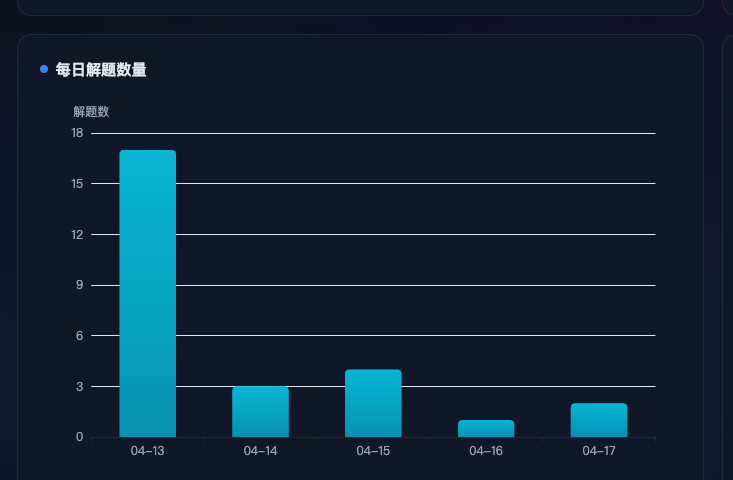
总体token花费(只统计了GLM的,实际消耗会比这个低,总体应该在1.8B左右,有一部分是零界的Agent打的。)
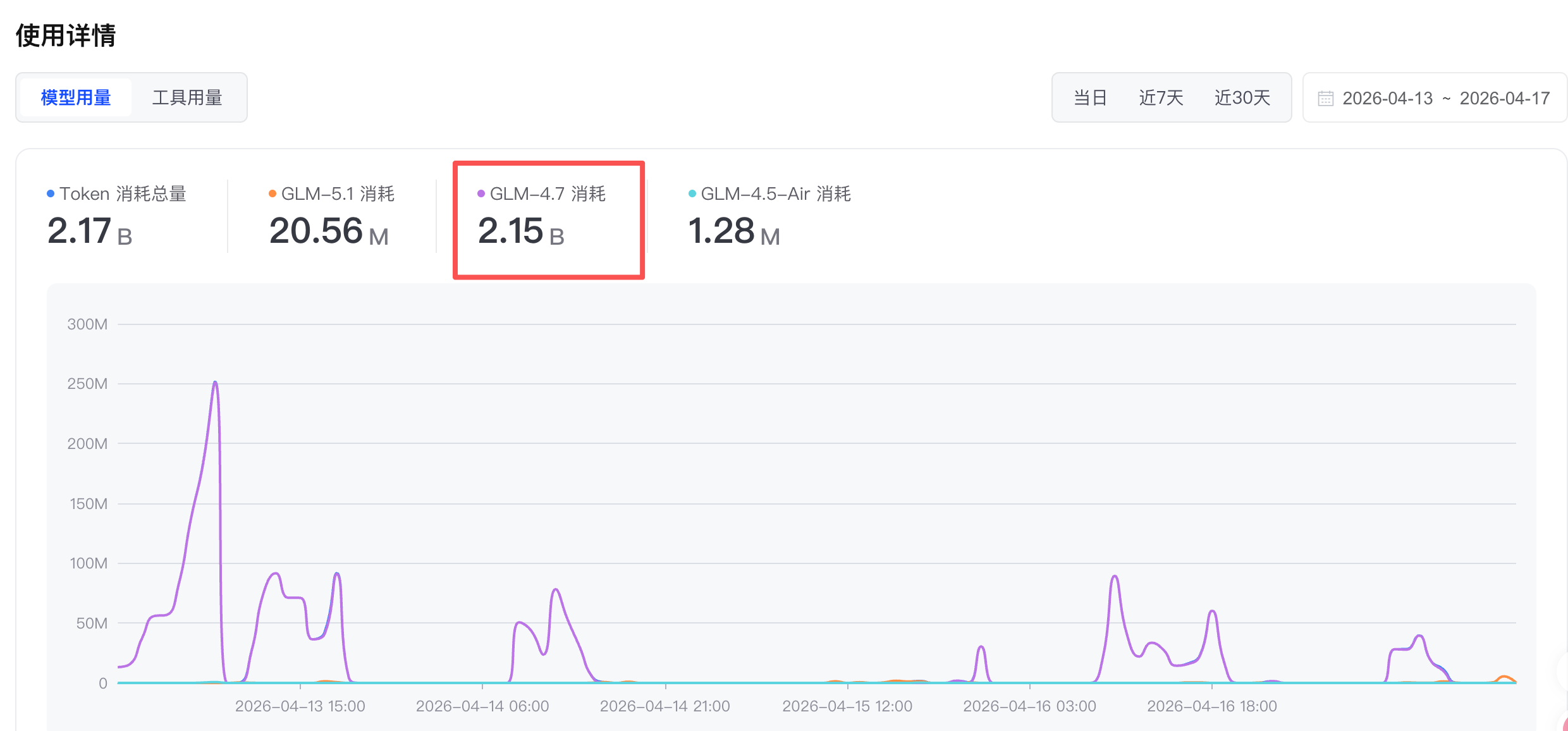
Agent 核心介绍
总体的架构如下:
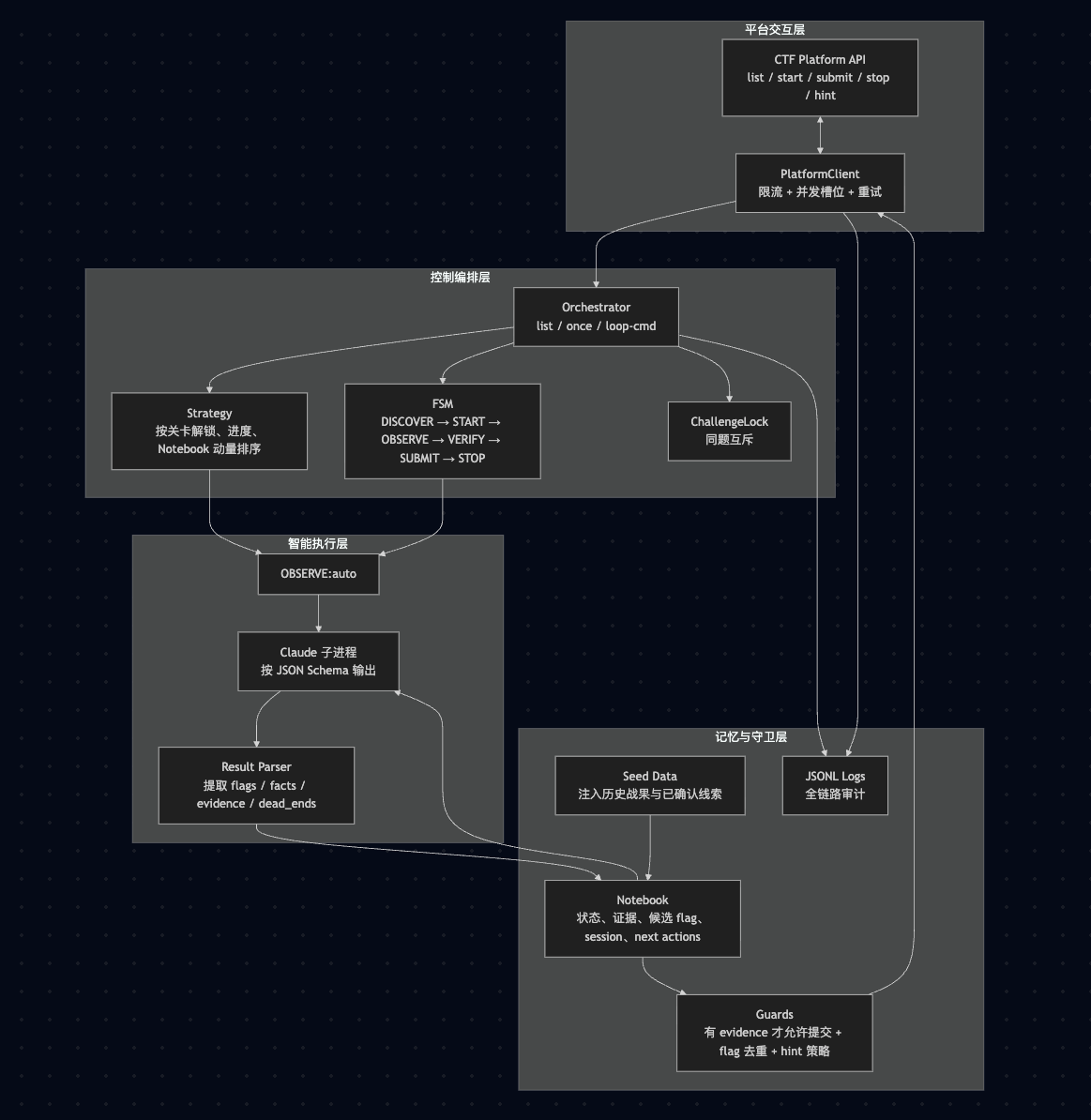
核心思路是:把不确定的漏洞探索交给 LLM,把确定性的状态、调度、限流、提交与记忆交给工程代码。
就是把大模型放进一个边界明确的流程里。Claude Code 只负责 OBSERVE 阶段,去看目标、尝试攻击、整理结果,然后按固定 JSON 格式把结论吐出来;像启停实例、调用平台 API、提交 Flag 这种会直接影响比赛状态的动作,还是得由程序自己兜住。
Notebook 记忆这层,如果每次重试都让模型从头看一遍题,成本太高,而且特别容易重复走弯路。所以我给每道题都做了一份持续更新的记录,把入口、事实、证据、攻击面、候选 Flag、失败路径、下一步动作信息都存下来。这样下一轮再跑的时候,不是“重新来一次”,而是接着上一次继续推进。
调度这块是比赛后期才改,动态闯关的策略,优先做当前关卡、已经有进展的题,以及剩余 Flag 更多的题,以获取更高的分数。
至于Claude Code层主要是配置了些Skill 和基础工具,核心思想是简单,更多是由模型来自我控制,从比赛来说这里面最有用的是vulhub的漏洞复现说明和对应的POC,因为第二关都是CVE的漏洞复现和变种利用。

后续发现上述的核心想法与AK完所有题目的淚笑师傅的设计思路有些大致相同,但不同的是本人实现的非常粗糙,详情见文章:https://mp.weixin.qq.com/s/DlpEH7bVr0xi0VawPJs3XA
反思与启发
比赛经验上:
1、赛前准备,需要考虑赛制、赛题的类型并进行充分的模拟和测试,考虑各种外部因素(网络,资源等等),降低正式比赛的风险。
2、比赛过程中,需要冷静的思考,珍惜每一次调试机会,建立快速分析定位当前状况和迭代优化的流程方法。
后续的持续推进,核心还是要不断的实践总结,探索大模型的界限,我认为下面几个问题是绕不开的:
1、充分测试并明确不同模型的知识/能力边界,建立底线标准。
2、收集和整理深入分析漏洞原理、复现的知识库
3、收集和整理一些基础必须的工具和对应的说明Skill
4、更优地复用模型的尝试路径、事实、攻击向量,并解决可能的历史上下文爆炸导致的跑偏问题
总结
从比赛来说,因为赛制的原因,得分随着解题的人数递减。
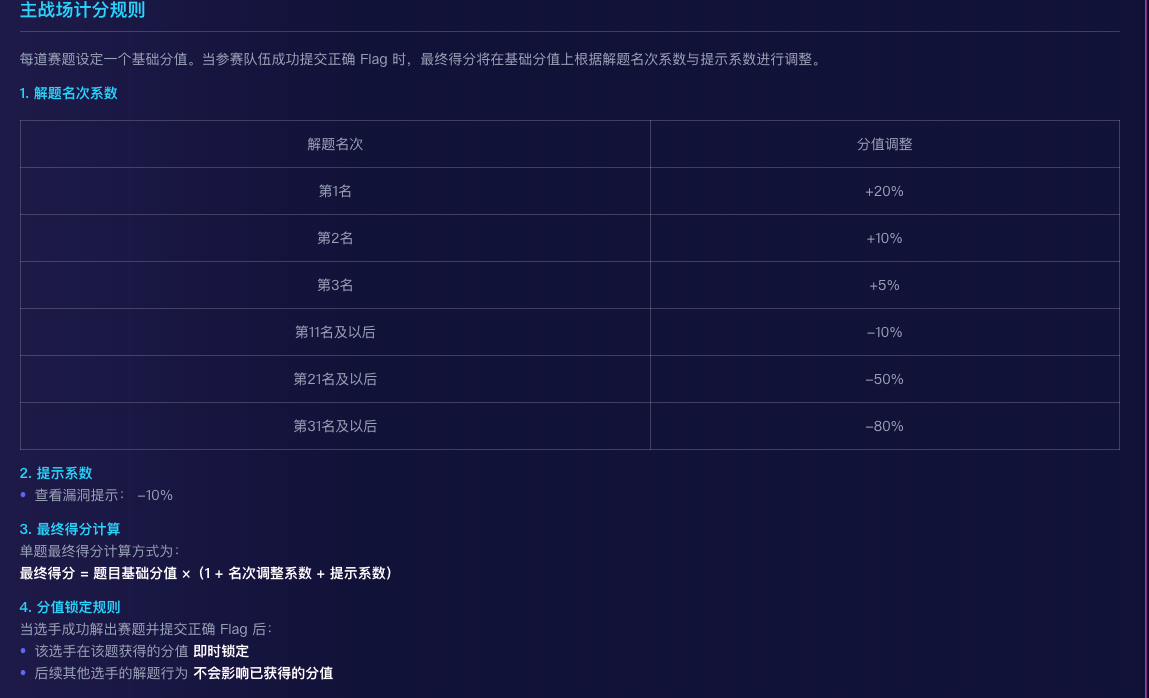
一个好的模型,提供了基础下限,加上系统(软件)成熟度高,那么基本上就可以拿到一个比较靠前的排名。
因为一旦有了先发优势,后面同水平的队伍想追上来就比较难了。
至于出色的系统设计,更多是来争夺TOP排名的,起到提高上限的作用。
系统(软件)成熟度高、模型好、出色的系统工程设计是拿到好名次的必备因素。
水平有限,一家之言,如有不妥,忘君轻喷。